Feature Augmented Memory with Global Attention Network for VideoQA
JiayinCai, Chun Yuan, Cheng Shi, Lei Li, Yangyang Cheng, and Ying Shan
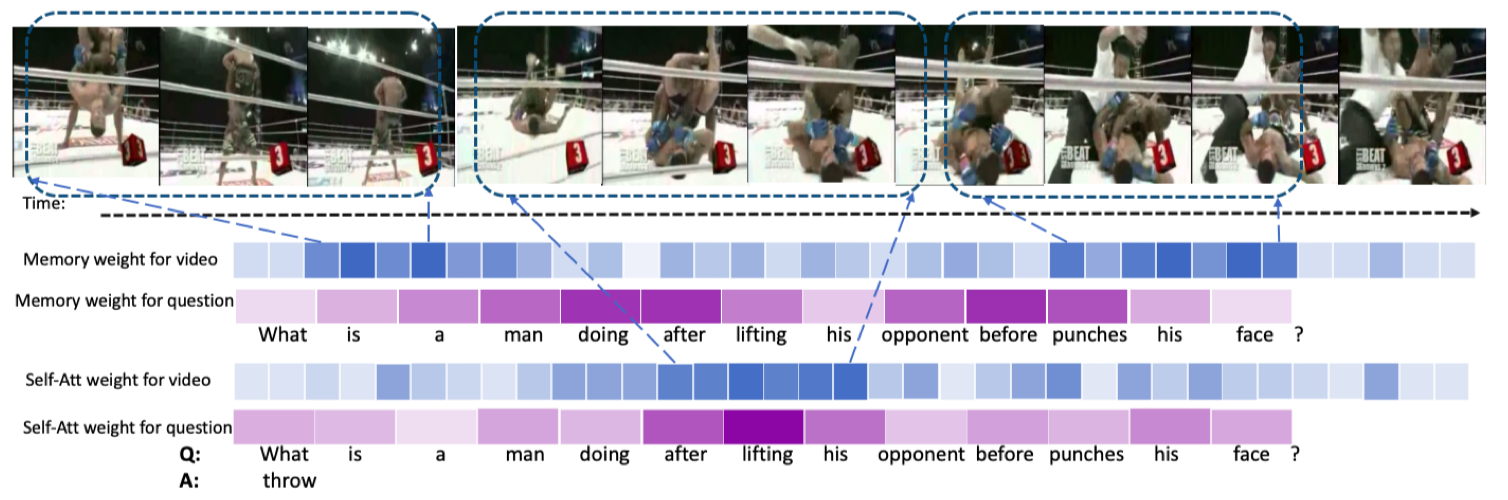
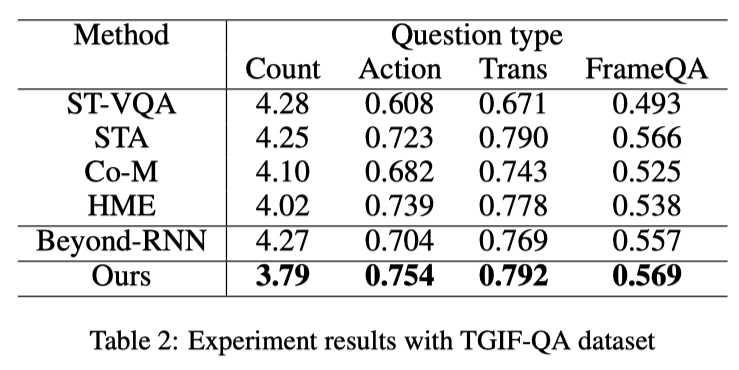
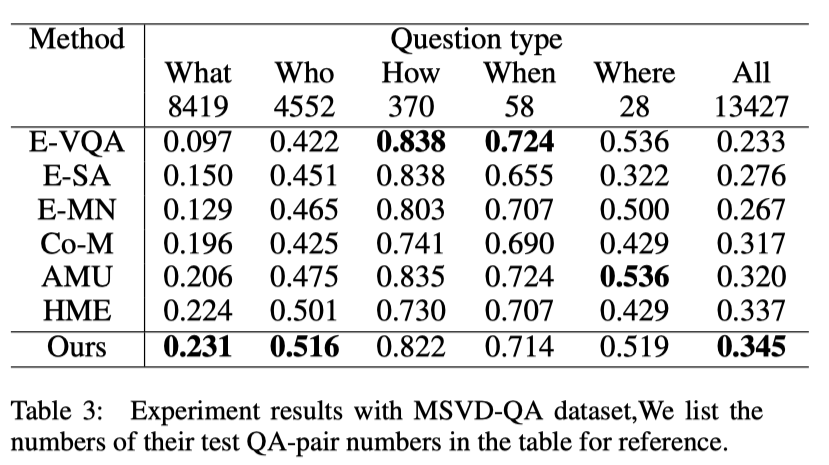
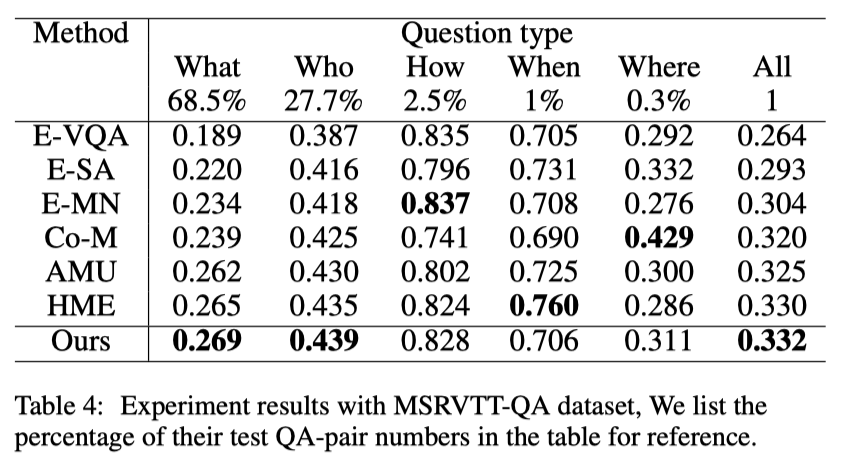
Recently, Recurrent Neural Network (RNN) based methods and Self-Attention (SA) based methods have achieved promising performance in Video Question Answering (VideoQA). Despite the success of these works, RNN-based methods tend to forget the global semantic contents due to the inherent drawbacks of the recurrent units themselves, while SA-based methods cannot precisely capture the dependencies of the local neighborhood, leading to insufficient modeling for temporal order. To tackle these problems, we propose a novel VideoQA framework which progressively refines the representations of videos and questions from fine to coarse grain in a sequence-sensitive manner. Specifically, our model improves the feature representations via the following two steps: (1) introducing two fine-grained feature-augmented memories to strengthen the information augmentation of video and text which can improve the memory capacity by memorizing more relevant and targeted information. (2) appending the self-attention and co-attention module to the memory output thus the module is able to capture global interaction between high-level semantic informations. Experimental results show that our approach achieves state-of-the-art performance on VideoQA benchmark datasets.

© 2020. All rights reserved | Design by Benjamin Zhang.